
 2 hours ago
16
2 hours ago
16
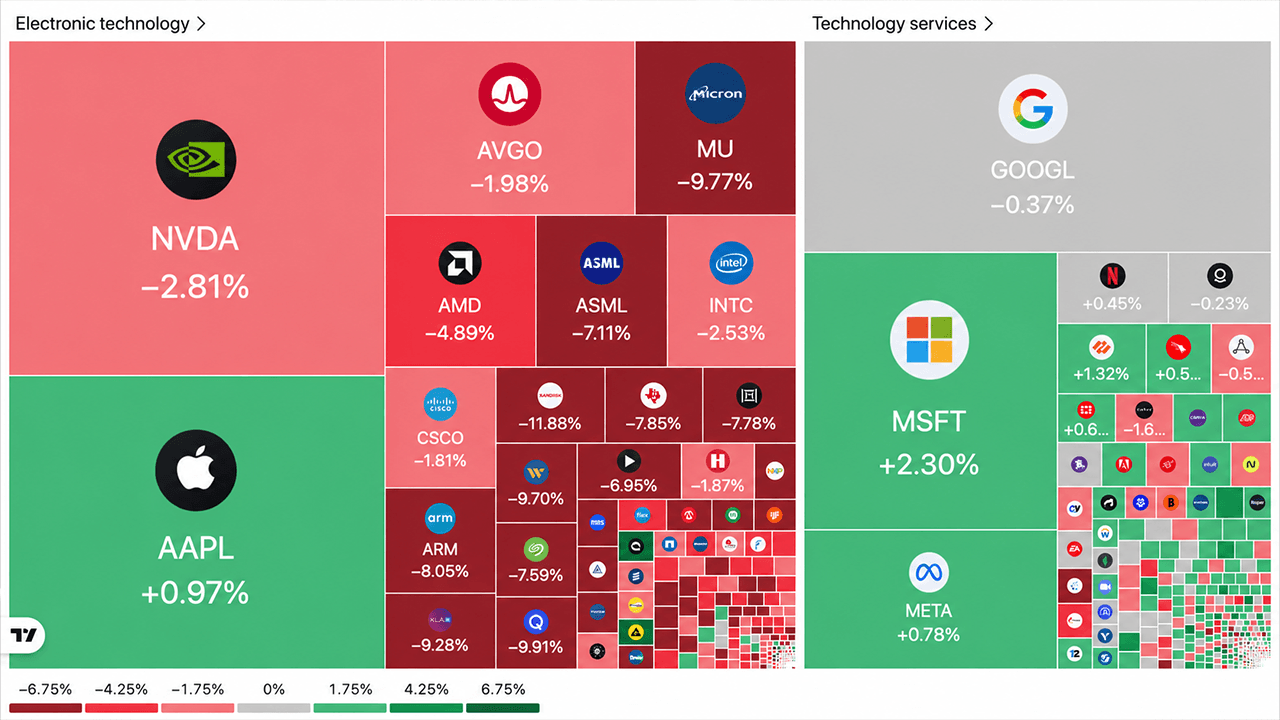
OpenAI is done renting its future from Nvidia. The company announced a partnership with Broadcom to develop custom AI accelerators specifically optimized for large language models, with a deployment target stretching from the second half of 2026 through the end of 2029.
The scale is staggering: 10 gigawatts of custom AI accelerators.
What the partnership actually looks like
The division of labor here is clean. OpenAI handles accelerator design, bringing its deep understanding of LLM workloads directly into the silicon architecture. Broadcom takes responsibility for development, manufacturing, and deployment of those systems, integrating them with its own Ethernet networking technology.
This isn’t OpenAI’s first flirtation with custom chips. Reports surfaced in September 2025 that the company was working with Broadcom on an “XPU” accelerator chip earmarked for 2026 production. The October 13 announcement confirms and massively expands that effort.
“Developing our own accelerators adds to the broader ecosystem,” said OpenAI CEO Sam Altman.
Broadcom CEO Hock Tan framed the ambition more directly, describing the goal as to “co-develop and deploy 10 gigawatts of next generation accelerators.”
Installations will roll out across OpenAI’s own facilities and affiliated data centers.
Why OpenAI needs its own silicon
OpenAI reportedly has more than 800 million weekly active users hitting its cloud-based AI services. Running large language models at that scale is enormously expensive, and custom accelerators let OpenAI bake its architectural insights directly into hardware — instead of writing software that works around a chip’s limitations, you build the chip around your software’s exact needs.
This is the same playbook Google ran with its TPU (Tensor Processing Unit) chips. Amazon followed with its Trainium and Inferentia chips for AWS. Microsoft has its Maia accelerators.
What this means for the competitive landscape
Broadcom’s Ethernet networking integration is a significant detail. AI inference at scale isn’t just about fast chips — it’s about moving data between chips efficiently. By coupling its networking expertise with OpenAI’s accelerator designs, Broadcom can offer an end-to-end solution.
The 2026-2029 deployment timeline matters for anyone modeling OpenAI’s financials. Custom chips take time to deliver returns, but once operational, they could dramatically reduce OpenAI’s per-query compute costs. At 800 million weekly active users and growing, even modest efficiency gains per inference translate to savings measured in billions annually.
Disclosure: This article was edited by Editorial Team. For more information on how we create and review content, see our Editorial Policy.








 English (US) ·
English (US) ·