
 1 month ago
40
1 month ago
40
I backtested a candle pattern published by Michael Harris, showing positive results
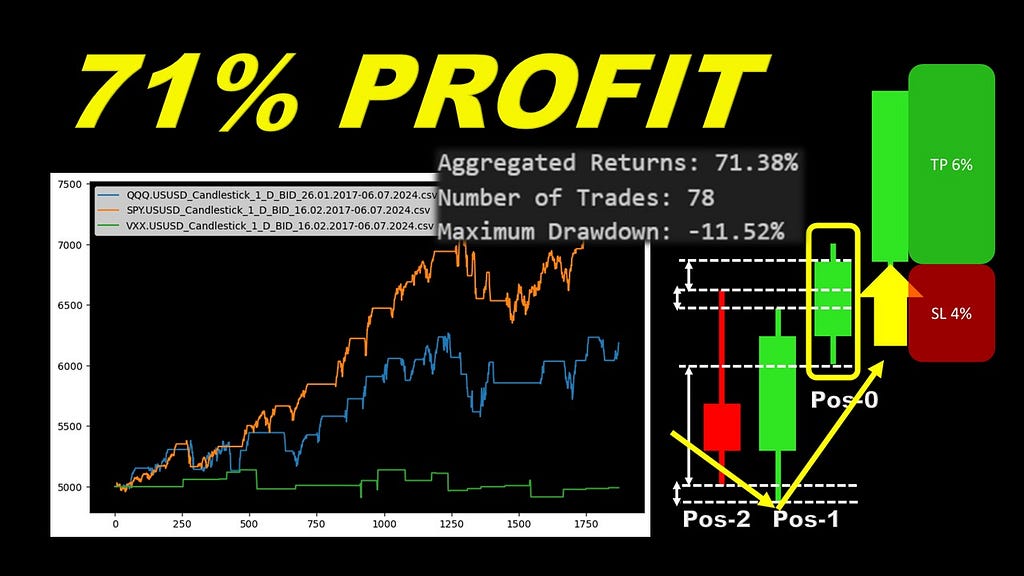
Algorithmic trading enthusiasts are always seeking robust strategies, and candle patterns are a timeless favorite. In this article, we will go through a powerful pattern from Michael Harris’s book, tested rigorously using Python. This simple yet effective strategy demonstrated a 65% win rate and a 71% profit on major stocks like the S&P 500. With step-by-step coding guidance and insights into the entry criteria, this is a must-read for anyone looking to elevate their trading game using automation.
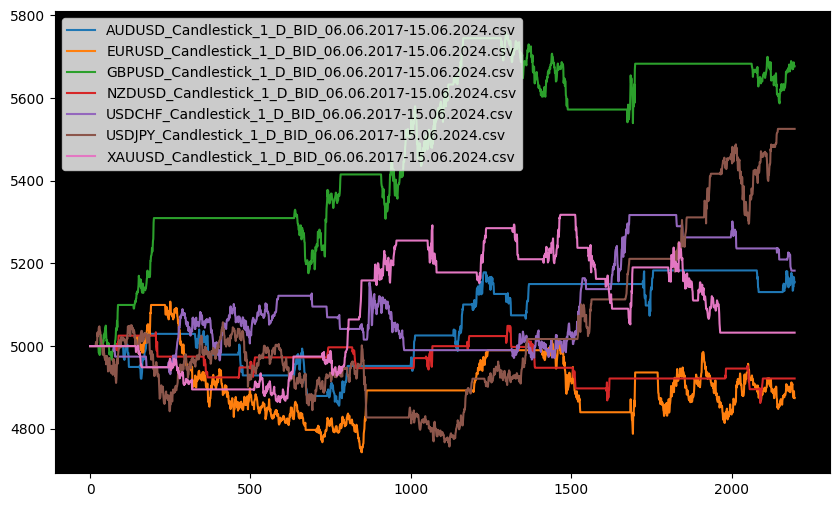
The full backtest results will be presented in the following equity chart:
1. Preparing the Data: Reading and Cleaning Candle Data
import pandas as pdimport pandas_ta as ta
from tqdm import tqdm
import os
import numpy as np
import plotly.graph_objects as go
from plotly.subplots import make_subplots
tqdm.pandas()
def read_csv_to_dataframe(file_path):
df = pd.read_csv(file_path)
df["Gmt time"] = df["Gmt time"].str.replace(".000", "")
df['Gmt time'] = pd.to_datetime(df['Gmt time'], format='%d.%m.%Y %H:%M:%S')
df = df[df.High != df.Low]
df.set_index("Gmt time", inplace=True)
return df
def read_data_folder(folder_path="./data"):
dataframes = []
file_names = []
for file_name in tqdm(os.listdir(folder_path)):
if file_name.endswith('.csv'):
file_path = os.path.join(folder_path, file_name)
df = read_csv_to_dataframe(file_path)
dataframes.append(df)
file_names.append(file_name)
return dataframes, file_names
The first step in any backtesting project is to prepare the data, and this Python script ensures the data is clean and structured for analysis. The code imports essential libraries like pandas for data manipulation, pandas_ta for technical analysis indicators, and plotly for visualization.
- The read_csv_to_dataframe function processes individual CSV files, ensuring timestamps are properly formatted and invalid rows (where High equals Low) are removed.
- The read_data_folder function scans a folder of CSV files, processes them using read_csv_to_dataframe, and returns a list of cleaned dataframes along with their filenames. This function is used when we need to run the strategy on more than one asset for example using multiple data files.
- The use of tqdm provides a progress bar, making it easy to monitor the processing of large datasets.
The data files I used and the full python code with a video walk-through are available on YouTube if you need more details:
2. Implementing the Candle Pattern Logic
def total_signal(df, current_candle):current_pos = df.index.get_loc(current_candle)
c1 = df['High'].iloc[current_pos] > df['Close'].iloc[current_pos]
c2 = df['Close'].iloc[current_pos] > df['High'].iloc[current_pos-2]
c3 = df['High'].iloc[current_pos-2] > df['High'].iloc[current_pos-1]
c4 = df['High'].iloc[current_pos-1] > df['Low'].iloc[current_pos]
c5 = df['Low'].iloc[current_pos] > df['Low'].iloc[current_pos-2]
c6 = df['Low'].iloc[current_pos-2] > df['Low'].iloc[current_pos-1]
if c1 and c2 and c3 and c4 and c5 and c6:
return 2
# Add the symmetrical conditions for short (go short) if needed
c1 = df['Low'].iloc[current_pos] < df['Open'].iloc[current_pos]
c2 = df['Open'].iloc[current_pos] < df['Low'].iloc[current_pos-2]
c3 = df['Low'].iloc[current_pos-2] < df['Low'].iloc[current_pos-1]
c4 = df['Low'].iloc[current_pos-1] < df['High'].iloc[current_pos]
c5 = df['High'].iloc[current_pos] < df['High'].iloc[current_pos-2]
c6 = df['High'].iloc[current_pos-2] < df['High'].iloc[current_pos-1]
if c1 and c2 and c3 and c4 and c5 and c6:
return 1
return 0
This step defines the core of the strategy by identifying the specific candle pattern that signals entry points. The function total_signal evaluates whether the conditions for a pattern are met for a given candle.
Key components of the pattern logic:
- Current Candle Position: Using df.index.get_loc(current_candle), the function identifies the position of the current candle in the DataFrame.
Conditions for Long Entry:
- Condition 1: The high of the current candle is greater than its closing price, indicating an upper wick.
- Condition 2: The closing price of the current candle is greater than the high of the candle at position -2.
- Condition 3: The high of the candle at position -2 is greater than the high of the candle at position -1.
- Condition 4: The high of the candle at position -1 is greater than the low of the current candle.
- Condition 5: The low of the current candle is greater than the low of the candle at position -2.
- Condition 6: The low of the candle at position -2 is greater than the low of the candle at position -1.
Conditions for Short Entry:
- Symmetrical to the long entry logic, focusing on lower wicks and downward momentum.
If all the conditions for a long entry are satisfied, the function returns 2. For a short entry, it returns 1. If neither set of conditions is met, it returns 0, signaling no trade.
This logic translates the visual pattern into quantifiable rules, enabling its automated detection during backtesting. Next, we’ll visualize the signals on price chart and integrate this logic into a full trading strategy.
3. Visualizing Entry Points on the Candlestick Chart
def add_total_signal(df):df['TotalSignal'] = df.progress_apply(lambda row: total_signal(df, row.name), axis=1)
return df
def add_pointpos_column(df, signal_column):
"""
Adds a 'pointpos' column to the DataFrame to indicate the position of support and resistance points.
Parameters:
df (DataFrame): DataFrame containing the stock data with the specified SR column, 'Low', and 'High' columns.
sr_column (str): The name of the column to consider for the SR (support/resistance) points.
Returns:
DataFrame: The original DataFrame with an additional 'pointpos' column.
"""
def pointpos(row):
if row[signal_column] == 2:
return row['Low'] - 1e-4
elif row[signal_column] == 1:
return row['High'] + 1e-4
else:
return np.nan
df['pointpos'] = df.apply(lambda row: pointpos(row), axis=1)
return df
def plot_candlestick_with_signals(df, start_index, num_rows):
"""
Plots a candlestick chart with signal points.
Parameters:
df (DataFrame): DataFrame containing the stock data with 'Open', 'High', 'Low', 'Close', and 'pointpos' columns.
start_index (int): The starting index for the subset of data to plot.
num_rows (int): The number of rows of data to plot.
Returns:
None
"""
df_subset = df[start_index:start_index + num_rows]
fig = make_subplots(rows=1, cols=1)
fig.add_trace(go.Candlestick(x=df_subset.index,
open=df_subset['Open'],
high=df_subset['High'],
low=df_subset['Low'],
close=df_subset['Close'],
name='Candlesticks'),
row=1, col=1)
fig.add_trace(go.Scatter(x=df_subset.index, y=df_subset['pointpos'], mode="markers",
marker=dict(size=10, color="MediumPurple", symbol='circle'),
name="Entry Points"),
row=1, col=1)
fig.update_layout(
width=1200,
height=800,
plot_bgcolor='black',
paper_bgcolor='black',
font=dict(color='white'),
xaxis=dict(showgrid=False, zeroline=False),
yaxis=dict(showgrid=False, zeroline=False),
showlegend=True,
legend=dict(
x=0.01,
y=0.99,
traceorder="normal",
font=dict(
family="sans-serif",
size=12,
color="white"
),
bgcolor="black",
bordercolor="gray",
borderwidth=2
)
)
fig.show()
After identifying the candle patterns, the next step is to map them to the dataset and visualize the results. This section introduces functions to apply the pattern logic, mark entry points, and plot the signals on a candlestick chart.
In the following image we can see sample of the data with the purple points signaling a pattern occurrence, if the point is below the candle it signals a bullish pattern and in the opposite direction if the point is above the candle it signals a bearish direction.
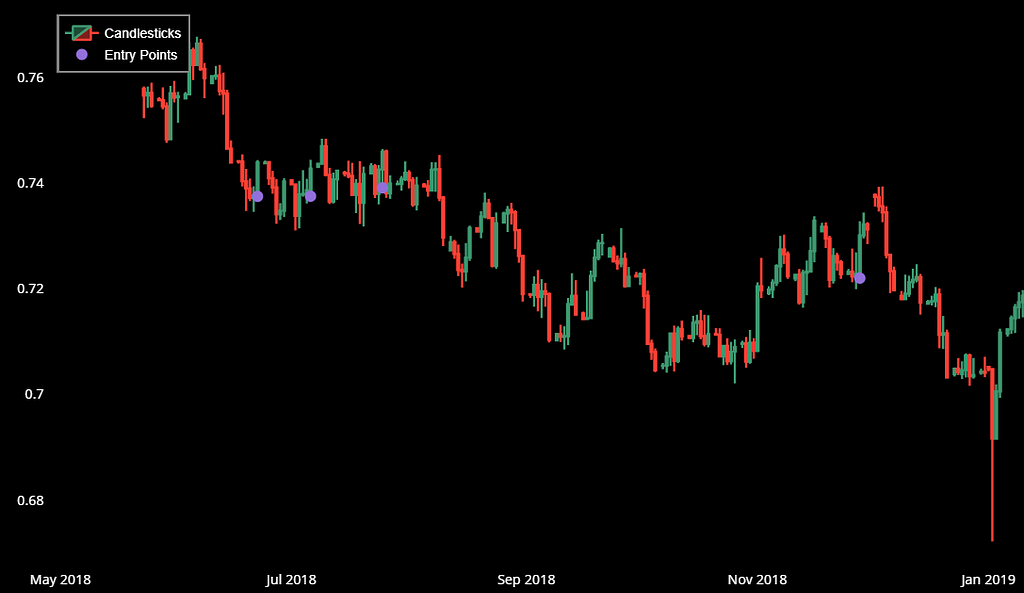
4. Backtesting the Strategy Across Multiple Dataframes
from backtesting import Strategyfrom backtesting import Backtest
def SIGNAL():
return df.TotalSignal
class MyStrat(Strategy):
mysize = 0.1 # Trade size
slperc = 0.04
tpperc = 0.02
def init(self):
super().init()
self.signal1 = self.I(SIGNAL) # Assuming SIGNAL is a function that returns signals
def next(self):
super().next()
if self.signal1 == 2 and not self.position:
# Open a new long position with calculated SL and TP
current_close = self.data.Close[-1]
sl = current_close - self.slperc * current_close # SL at 4% below the close price
tp = current_close + self.tpperc * current_close # TP at 2% above the close price
self.buy(size=self.mysize, sl=sl, tp=tp)
elif self.signal1 == 1 and not self.position:
# Open a new short position, setting SL based on a strategy-specific requirement
current_close = self.data.Close[-1]
sl = current_close + self.slperc * current_close # SL at 4% below the close price
tp = current_close - self.tpperc * current_close # TP at 2% above the close price
self.sell(size=self.mysize, sl=sl, tp=tp)
Backtesting Framework
- Defining the Strategy:
- The MyStrat class inherits from the Strategy module in the backtesting library:
- Signal Integration: The SIGNAL function supplies the signals generated earlier.
- Position Management: A new long position is opened when the signal is 2 (long entry), with stop loss (SL) and take profit (TP) levels dynamically calculated based on percentages of the closing price.
Loading multiple data files
folder_path = "./data_forex"dataframes, file_names = read_data_folder(folder_path)
for i, df in enumerate(dataframes):
print("working on dataframe ", i, "...")
df = add_total_signal(df)
df = add_pointpos_column(df, "TotalSignal")
dataframes[i] = df # Update the dataframe in the list
This code reads a folder of data files and loads the data into multiple data frames.
Backtest Execution
results = []heatmaps = []
for df in dataframes:
bt = Backtest(df, MyStrat, cash=5000, margin=1/5, commission=0.0002)
stats, heatmap = bt.optimize(slperc=[i/100 for i in range(1, 8)],
tpperc=[i/100 for i in range(1, 8)],
maximize='Return [%]', max_tries=3000,
random_state=0,
return_heatmap=True)
results.append(stats)
heatmaps.append(heatmap)
- Each dataframe is tested using the Backtest module, initialized with $5,000 starting cash, a 20% margin, and a commission of 0.02%.
- Parameters like slperc (stop loss) and tpperc (take profit) are optimized using a grid search to maximize returns.
Aggregating Results
agg_returns = sum([r["Return [%]"] for r in results])num_trades = sum([r["# Trades"] for r in results])
max_drawdown = min([r["Max. Drawdown [%]"] for r in results])
avg_drawdown = sum([r["Avg. Drawdown [%]"] for r in results]) / len(results)
win_rate = sum([r["Win Rate [%]"] for r in results]) / len(results)
best_trade = max([r["Best Trade [%]"] for r in results])
worst_trade = min([r["Worst Trade [%]"] for r in results])
avg_trade = sum([r["Avg. Trade [%]"] for r in results]) / len(results)
print(f"Aggregated Returns: {agg_returns:.2f}%")
print(f"Number of Trades: {num_trades}")
print(f"Maximum Drawdown: {max_drawdown:.2f}%")
print(f"Average Drawdown: {avg_drawdown:.2f}%")
print(f"Win Rate: {win_rate:.2f}%")
print(f"Best Trade: {best_trade:.2f}%")
print(f"Worst Trade: {worst_trade:.2f}%")
print(f"Average Trade: {avg_trade:.2f}%")
Results across all dataframes are aggregated to calculate key metrics:
- Aggregated Returns: Total percentage return across all datasets.
- Number of Trades: Total number of trades executed.
- Maximum and Average Drawdown: The deepest and average dips in the account balance.
- Win Rate: Percentage of trades that ended profitably.
- Best and Worst Trade: The highest and lowest returns from individual trades.
- Average Trade Performance: Average return per trade.
Plotting The Equity Curves
equity_curves = [stats['_equity_curve']['Equity'] for stats in results]max_length = max(len(equity) for equity in equity_curves)
# Pad each equity curve with the last value to match the maximum length
padded_equity_curves = []
for equity in equity_curves:
last_value = equity.iloc[-1]
padding = [last_value] * (max_length - len(equity))
padded_equity = equity.tolist() + padding
padded_equity_curves.append(padded_equity)
equity_df = pd.DataFrame(padded_equity_curves).Timport matplotlib.pyplot as plt
equity_df.plot(kind='line', figsize=(10, 6), legend=True).set_facecolor('black')
plt.gca().spines['bottom'].set_color('black')
plt.gca().spines['left'].set_color('black')
plt.gca().tick_params(axis='x', colors='black')
plt.gca().tick_params(axis='y', colors='black')
plt.gca().set_facecolor('black')
plt.legend(file_names)
5. Conclusion
We can see that the pattern reults are positive on some assets and not very promising on others. The issue here is that I tested this strategy on Forex data but Michael Harris described it in his book for stocks data, this might be affecting the results as well. Still I strongly believe that if we identify 5 patterns as this one and we run these simultaneously on let’s say 10 different assets, this might be a good starter for a trading system, that can be easily automated at least signaling potential trades and sending alerts to the human trader. Obviously the system is not fully automated because a trader still needs to verify the validity of the signal, but the algorithm is doing the waiting time and probing the market on behalf of the trader… which is more comfortable than trading in full manual mode.
This Simple Candle Pattern Strategy Delivered 65% Win Rate in Backtesting was originally published in The Capital on Medium, where people are continuing the conversation by highlighting and responding to this story.








 English (US) ·
English (US) ·